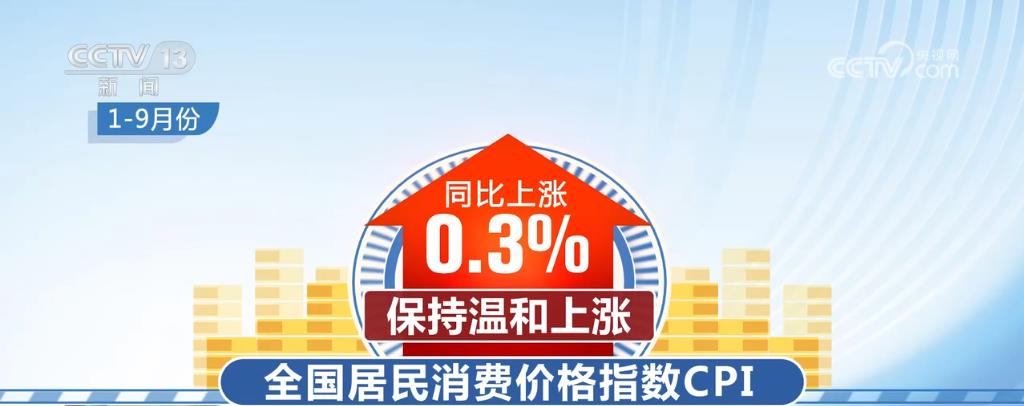
Recently, Ecommerce Europe and EuroCommerce jointly released the 2021 European E-commerce Report. According to the data, the total value of e-commerce in Europe increased to 757 billion euros in 2020, up 10% from 690 billion euros in 2019.
According to the agency’s forecast, by 2025, the proportion of sales of e-commerce platforms in the European cross-border e-commerce market will rise from the current 58% to 65%, and the future of the European cross-border e-commerce market is immeasurable.
Here, Hugo cross-border lists several cross-border platforms worthy of attention in Europe, taking you to explore the rules and advantages of various cross-border e-commerce platforms in the European market.
Table of European e-commerce platforms: (in no particular order)
1、Manomano
2、Allegro
3、Fnac
4、OZON
5、eMAG
6、Fyndiq
7、Onbuy
8、OTTO
9、Spartoo
10、Cdiscount
11. Lotte France
12、Back Market
13、ePrice
14、Worten
15、 Bol.com
16、Fruugo
17、Joom
18、UMKA
19. Moga MMOGA POWER
20、Wisecart
21、Rue du Commerce
22、MYTOYS GROUP
1、Manomano:
The first e-commerce platform in Europe focusing on home DIY and gardening market is also the only online platform specializing in home decoration and garden gardening.
Founded in 2013, ManoMano is a professional online home decoration leader with 10 million products. The platform has 50 million monthly visits, 7 million online active customers and 50 million monthly independent visits. By the end of 2020, the total turnover has reached 1.21 billion euros.
Compared with other local hardware stores and DIY stores, ManoMano offers a wider range of products, thus providing consumers with more choices than their peers. Most of the customer comments in the comment area of the website are very positive. People will share their positive experience in using these DIY products, home decorations and gardening products.
Entry requirements:
1. Have a company license and RIB (French bank account number);
2. There is a European VAT number;
3. SKU quantity: 100 or more is the best;
4. It is best to have operators who master French/English.
Settlement fee:
1. Agent fee for ManoMano: 3,700 yuan (RMB);
2. Monthly rental of ManoMano platform: The monthly rental of the platform is 100 euros/month/country in EU countries (France, Germany, Italy and Spain) and 50 pounds/month in the UK, and the value-added tax is extra.
3. The commission depends on your product range;
4. ManoMano logistics cost: ManoMano has a price list for reference according to the size and weight of your products;
5. Other expenses: No hidden expenses.
ManoMano official cooperation channel, click to view > > >
2、Allegro:
Allegro is not only the dominant e-commerce platform in Poland, but also ranks in the top five in the whole European e-commerce market. According to the official statistics of the platform, the number of monthly active users reaches 18 million, accounting for nearly half of the total population of Poland.
Platform advantages:
1. There is no fixed fee for Allegro platform, only commission and advertising fee.
2. The platform language threshold is low, Polish itself is simple, and translation software is basically accurate; And allegro’s seller backstage has an English/Polish interface to switch. In addition, through Hugo’s presence, Hugo will help you to connect with the Polish local platform with good Chinese, which will help to check and correct word errors, and you don’t have to worry about language when uploading products.
3. There is a Chinese operation tutorial to help the seller get started quickly.
Entry requirements:
1. Business license (self-employed individuals can move in);
2. Identification certificates of legal persons and shareholders (ID card required+passport or driver’s license or Hong Kong and Macao pass, you can choose one of three, and shareholders’ information needs to be given in full, and none of them can be leaked);
3. Payoneer or pingpong or LianLian account receives payment statement.
Note: At present, the category does not support catering or real estate.
Platform fee:
According to different categories, different commissions are charged, and in addition, advertising fees are charged according to the situation of advertising.
Collection cycle:
Because the platform does not charge a deposit, the first three months of the store is the assessment period, and the payment is made once every 45 days. After the assessment period, you can apply for payment twice a month (on the 1st and 14th of each month), and sellers with excellent performance can apply for payment once every 7 days.
Through Hugo, you can enjoy the following exclusive benefits:
1. Free of commission until the end of the following month.
2. Free professional monthly service (value 330 yuan)
3, 100 times free of fixed-fee ranking advertisements (the value of answering questions is 3200 yuan), and the commission surcharge is 50% off.
4. Provide hot search terms, competitive price, sales volume and sales trend of specific products on the platform to help sellers improve their competitiveness.
Allegro official cooperation channel, click to view > > >
3、Fnac:
The third French retailer of cultural products and electrical products, and the preferred platform for purchasing electronic high-tech products in the French.
Key categories: 3C electronics, household appliances and furniture.
Platform advantages:
1. There are more than 700 physical stores in France, with dual online and offline drainage.
2. The platform of choice for brands and boutique vendors is trustworthy.
3, 0 advertising costs, advertising forms are diverse, helping sellers to explode orders.
4, a single fast, suitable for creating explosions.
5, fast payment, once every 5 days.
Entry threshold:
1. Must have experience in cross-border e-commerce market;
2. It is best to have French/English after-sales customer service;
3, it is best to ship in Europe; It is recommended to have an overseas warehouse (this is not a necessary condition, but it is necessary for the arrival date to be 10 natural days, that is, the logistics timeliness is required to be within 10 days).
Payment method:
Lianlian, pingpong, payoneer, Air Cloud Convergence, Wan Li Convergence.
With Hugo, you can enjoy the following exclusive services:
1. Free of the monthly rental fee for the platform for 6-9 months (worth 2500 yuan).
2, the exclusive green channel to open a store, 5-7 working days to open a store quickly.
3. Exclusive shelf training
4, the platform quality novice seller traffic tilt
5, hot product recommendation: analyze the key data of the platform to help create explosions.
6. KYC audit assistance: Chinese tutorial video guidance, official guidance for quick review.
7, has settled in the seller’s exclusive community VIP Q&A
Fnac official cooperation entry channel, click to view > > >
4、OZON:
OZON is one of the earliest online shopping and retail platforms in Russia, and its product categories cover most FMCG categories. OZON’s sales have grown rapidly since 2019. In 2019, OZON’s sales increased by 93% to 80.7 billion rubles.
Platform advantages:
1. The threshold is low, and it is friendly to new sellers-the whole platform can’t put advertisements, and there is no need to burn money to advertise, so as to avoid malicious competition among sellers.
2. Except for the commission, there is no other settlement fee.
3. It is not mandatory for the seller to have a Russian foundation. As long as English is input for uploading products, the background can automatically help the seller translate. Now the seller who has settled in through Hugo can also get a comprehensive Chinese version of the learning materials on the platform.
4, there is no designated logistics provider, as long as the seller has a good docking logistics provider, it can be used, requiring direct delivery from China and delivery within five days and 40 days.
5. Through Hugo’s presence, you can get the support of the official manager of OZON China to help the seller grow rapidly.
Entry requirements:
1. The seller who settled in through Hugo only needs to provide the original business license and the translated business license. Hugo can also help the seller translate without the translated business license.
2, the seller must use Wan Li remittance to collect money, and Hugo, the seller who does not have it, can also help to dock.
OZON official cooperation channel, click to view > > >
5、eMAG:
The largest e-commerce platform in Romania and the fastest growing e-commerce platform in Europe.
Applicable area:Romania, Bulgaria, Hungary
Platform advantages:
1. eMAG Marketplace has its own overseas warehouse in Romania, which is open to sellers in China. EMAG Marketplace adopts the mode of activating inventory after the goods arrive at the warehouse, and the terminal logistics will be delivered by eMAG itself, thus greatly optimizing the delivery timeliness performance of platform stores.
2. eMAG Marketplace has a professional Chinese account manager. It not only relieves the sellers of the worries of communication difficulties, but also provides free translation services for sellers in China. Translate the product description into Romanian and then help upload it.
3. eMAG Marketplace not only has a PC web version, but also is equipped with mobile phone software. Diversified drainage inlets also ensure the observability and stability of platform flow.
Platform cost;
1. There is no fixed fee
2, the commission from 7%
3. Storage fee
Collection cycle:Pay back twice a month
Open a shop through Hugo and enjoy the following exclusive benefits:
1, the first three months of overseas warehouse free of storage fees.
2. Free FBE storage fee for 3 months, and some products can be returned free of charge.
3. Free online and offline training and free promotion activities.
4. Free dedicated account manager and account manager support.
5. Give priority to quick entry, guide the whole process of opening a store, and improve the pass rate.
EMAG official cooperation channel, click to view > > >
6、Fyndiq:
Sweden’s largest e-commerce platform, established in 2010, has attracted a large number of loyal buyers by selling high-quality and cheap goods.
Sweden has a population of more than 10 million and strong consumption power. Its per capita GDP ranks 12th in the world, surpassing Germany, Britain and France.
Sweden has a highly developed economy and is famous for its "Swedish model" with high income, high taxes and high welfare. Swedes have a strong sense of paying taxes according to law, and everyone pays taxes consciously; As the largest B2C e-commerce platform in Sweden, Fyndiq adopts a unique "flash purchase" mode and "B2B2C" trading mode: each order generates two transactions, and the merchants VS Fyndiq and Fyndiq VS the buyer-VAT are directly paid to Fyndiq by the buyer, and then Fyndiq centrally pays to the Swedish tax authorities.
Entry requirements:
1. Business license of the enterprise
2. Registered VAT (providing registration certificate) in EU countries.
3. SKU quantity is greater than 3k.
4. The order must be delivered within 14 working days.
5. Payoneer’s account information is available.
6. Recommended by settled merchants or official partners of Fyndiq (Hugo is an official strategic partner of Fyndiq, which can help sellers to settle in quickly).
Fyndiq official cooperation channel, click to view > > >
7、OnBuy:
The fastest growing B2C e-commerce platform in the UK was established in November 2016 and was named the best enterprise in the UK.
Platform advantages:
1. Low commission: 5%-9%, and the monthly rent is 19-39 pounds.
2, fast payment, after the seller delivers the goods, unified PayPal will pay back the money immediately.
3. The operation of the platform is simple, and there are no complicated games and routines.
4. The platform has no self-service and does not need to compete with the platform.
Entry requirements:
1. Business license is required
2. Shops with other cross-border e-commerce platforms
3. There is a paypal collection account.
OnBuy official cooperation channel, click to view > > >
8、OTTO:
Germany is a leading provider of e-commerce solutions and services, ranking second in the global integrated B2C platform, and the largest online clothing, apparel and daily necessities retailer in Europe.
Hot-selling categories: clothing, furniture, 3c products.
Consumer groups: most of them are between the ages of 25 and 55, and 62% of customers are married women with above-average income.
Entry requirements:
1. Business license of German local company
2. The legal person can be contacted and needs to hold a passport for KYC audit.
3. The company needs to handle VAT and own Bescheinigung certificate in electronic commerce.
4, Germany local overseas warehouse delivery
5. Local DHL/Hermes distribution in Germany
6. German customer service
7. The goods use European EAN bar code (or UPC code).
Platform fees and payments:
1. Rent: 39.9 Euro/month
2. Commission: 7%-18%
3. Payment: the first Thursday 31 days after the delivery of the order.
4. According to German law, 19% VAT tax will be charged for this commission.
Platform logistics:
At present, only the self-delivery mode is supported: all merchants need to send goods from Germany to buyers (self-delivery through their own warehouses in Germany or overseas warehouses in Germany). DHL or Hermes must be used for distribution.
OTTO officially cooperated in the channel, click to view > > >
9、Spartoo:
With a warehouse of over 30000m2, Spartoo’s products are sold in more than 20 countries, including France, Germany, England, Italy, Spain, etc., with more than 1400 million visitors in Europe every month, making it a leading fashion shopping platform in France.
Entry requirements
1. Logistics aging within 7 days
2. Brand goods
3, only shoes, bags, beauty, accessories sellers.
4. Pay attention to consumer satisfaction.
5, high quality pictures
6. EAN code (not necessary, but strongly recommended)
7. Customer service reply within 24 hours.
Spartoo official cooperation channel, click to view > > >
10、Cdiscount:
The largest e-commerce platform in France, which belongs to Casino, one of the largest supermarkets in France, focuses on consumer electronics and household products, and is well received by consumers from all walks of life in France.
Traffic: 20 million UV/ month, and the active traffic maintained a growth of 10.8%.
Hot-selling categories: electronic products, mother and baby, home appliances, luggage, toys and home, etc.
Target audience: What does it take for a consumer group Cdiscount to settle in?
Market sites: France, Belgium, Germany, Luxembourg, Italy, Spain.
Platform features:
1. One-click sales to six European countries
2. FFM overseas warehousing and delivery services
3. Various marketing tools
4. The Best Search Optimization Website in France
Platform fee:
1. 39.99 Euro/month, excluding tax.
2. Commission 5%-20%
Platform collection:Third-party public account collection
Platform logistics:
1. straight hair and overseas warehouse FBC
2. Prescription requirements: 10-20 working days.
Through Hugo, you can enjoy the following exclusive benefits:
1. The new shop is free of rent for 6 months (worth 2,000 yuan).
2. The new store is free of storage fee and rented for 3 months.
3. The account manager directly interfaces with the platform, and 1v1 supports the seller’s operation.
Cdiscount official cooperation channel, click to view > > >
11. Rakuten Lotte France:
Rakuten France Lotte is the third most influential online shopping platform in France, and the loyal members of French Club R reached 8 million in 2020. The monthly average number of views is as high as 17 million, and 5,000 offline stores in France have been seamlessly connected to Rakuten’s e-commerce platform in France. In addition, there are 8,000 professional e-commerce seller stores around the world.
Platform advantages:
1. Fast payment cycle: 2 fixed payments a week, 8 times a month, to speed up your capital flow; The store has been operating for four months and its score is stable.
After that, you can apply for quick payment service. Submit the tracking number to get the payment back.
2. The platform shares the marketing components: the maximum rebate for the whole audience is 20%.
3. Platform support: free of monthly fees for the first three months, fast learning at low cost, and speeding up the billing.
4. Fast entry speed and low competition: there are less than 1,000 sellers in China.
5. No language barriers: the Chinese team provides all-round services. Monthly training allows you to understand the platform rules faster and issue orders quickly.
Entry requirements:
1. Cross-border payment bank account number is required.
2. Business license
French lotte official cooperation enters the channel, click to view > > >
12、Back Market:
Back Market is a leading market website dedicated to refurbishing electronic equipment, aiming to make refurbished equipment mainstream.
Many people in Europe have the habit of buying second-hand goods, so backmarket has expanded rapidly since its establishment, with monthly active users increasing by about 8%, covering the United States, France, Spain, Germany, Italy, Belgium, Britain and Austria.
Entry requirements:
1. Entry of enterprises (business license of mainland China)
2. ID photo of the resident (photo of shareholders whose shareholding system must be greater than 25%))
3. Report detailed feedback in real time.
4. Verify the product quality of the seller.
Back Market official cooperation channel, click to view > > >
13、ePrice:
Italy’s largest local e-commerce platform & the largest 3C electronic product e-commerce market.
Hot-selling categories: electronic technology products, household appliances, sporting goods, home gardening and personal care.
Target audience: 3C electronic consumption is dominant, accounting for 81% of males.
Platform features:
1. High exposure
2. Strong reliability
3, high safety
4. Low cost
5. Efficient customer service team
Platform fee:
1. The fee is 29 euros/month, excluding VAT, and the first three months are free.
2. Commission: 5%-8%, with different proportions charged according to different product categories.
Platform collection: a European bank account number is required.
Platform logistics: At present, only sellers can deliver goods by themselves, and return addresses in Europe or Germany are required.
EPrice official cooperation channel, click to view > > >
14、Worten:
Worten is a leading e-commerce platform in Portugal, with the highest brand awareness among the whole people, and 55% of the audience know this brand.
In 2019, more than 5 million Portuguese people shopped in Worten and had more than 230 physical stores.
There are more than 1.2 million SKUs in 3C household appliances, consumables and entertainment electronic equipment, with a customer price as high as 120 euros and annual sales of more than 110 million euros.
Hot-selling categories: mobile phones, 3C consumer products, entertainment electronics, IT, household appliances and digital cameras.
Platform advantages:
1. occupy 40% market share: it has the highest brand awareness among the whole people, and 55% of the audience knows the brand, occupying 40% market share, which is higher than Amazon Portugal.
2. Dual sites: You can operate Spanish and Portuguese sites or any of them with the same account.
3, offline store to online, online to physical store: instantly access more than 230 physical stores, you can place an order online and pick it up at the physical store.
4. 360-degree all-round customer service: 360-degree all-round customer service center and the support of sales and technical teams to support your various demands.
Entry requirements:
1. Professional B2C sellers only
2, logistics conditions meet the delivery to Portugal and Spain within 25 days.
3. Only brand-new products are available, and the sale of second-hand products is not supported for the time being.
Worten official cooperation channel, click to view > > >
15、 Bol.com:
Bol.com is the largest e-commerce platform in the Benelux region (Belgium, Netherlands, Luxemburg), with 11 million active customers, more than 23 million products and more than 30,000 retailers.
Entry qualification requirements
1. Customer service in Dutch, and telephone customer service can be provided at 9am-5pm Dutch time-
2, 30 days no reason to return.
3. VAT in EU countries
4. Companies registered in EU countries
5. European collection account
6. GMV of 1 million euros/year for mainstream platforms.
Bol.com official cooperation channel, click to view > > >.
16、Fruugo:
Frugo-making cross-border transactions easier, an e-commerce platform can reach potential consumers in as many as 46 countries around the world, and 85% of orders come from cross-border transactions.
Founded in Finland in 2006, it has received 40 million euros worth of investment from Nokia, Royal Dutch Shell and other companies.
Platform advantages:
1. The interface supports 28 languages: automatic translation technology can translate products into 28 languages, providing localized shopping experience for consumers.
2. Invest in search promotion marketing: invest a lot of money to bring search traffic to the seller’s product page. As long as consumers are searching for the products you sell, they can be found for you.
3. Local currency transaction: support local currency and various transaction methods to ensure that consumers can choose their preferred payment method.
4. Automatic currency exchange: trade with consumers in local currency, and fruugo bears the risks of currency conversion and foreign exchange.
5. Chinese account manager: You can enjoy Chinese account manager service through Hugo.
Fruugo officially cooperated in the channel, click to view > > >
17、Joom:
Joom is a well-known mobile e-commerce platform in Russia. Since it was launched in June 2016, it has experienced explosive growth and has become one of the fastest growing e-commerce platforms in the world. Joom is a brand-new and fast-growing mobile shopping platform. So far, Joom mobile has nearly 50 million downloads, and the order volume is increasing day by day.
Advantages of Joom platform
1. The application push function is powerful, attracting customers to return to the application through pop-up notification push.
2. Have an automated discount algorithm for each user. You only need to set the price of the goods, and we can promote the sales automatically.
3. Put personalized product advertisements on mobile phone users. It is the first company to realize the automatic delivery of all mobile phone advertisements.
4. There are many categories of products on the platform.
5, have their own logistics system, no need for sellers to pay logistics costs, multiple domestic collection points.
Platform rules:
1. 5%-15% commission
2. Lending in 14 days
Delivery within 3 or 2 days
Entry requirements:
1. Business license
2. Legal person ID card
3. The legal representative holds a positive photo of the ID card.
4. Bank account or Payoneer account information
5. Links to mainstream platform stores
Joom official cooperation channel, click to view > > >
18、UMKA:
UMKA is one of the largest online shopping websites for goods in China in Russian-speaking areas, and its products cover electronic products, household goods, audio-visual equipment, outdoor sports, auto parts and so on.
Customers can access the platform through mobile devices or computer websites. Relying on the strong and perfect warehouse distribution logistics system and the core advantages of localization of overseas management teams, the platform provides Russian-speaking netizens with high-standard localized shopping experiences such as high-quality goods, multiple payments, timely delivery, goods exchange and professional customer service.
China retailers can simply and directly reach about 350 million consumers in 12 Russian-speaking countries through UMKA platform.
UMKA investment direction introduction:
According to the demand of Russian market for China products, the commodities currently attracting investment include: household products, household appliances, 3C products, auto parts, outdoor products, hardware and building materials, and others.
Entry requirements:
1. The original scanned copy of the Business License of Enterprise as a Legal Person
2. A scanned copy of the original copy of the front and back of the legal representative’s ID card;
3. Power of attorney issued by the brand owner;
4. Trademark registration certificate or notice of acceptance of trademark registration application issued by the State Administration of Trademarks;
5. Product information package:
UMKA official cooperation channel, click to view > > >
19. Moga MMOGA POWER:
Europe’s largest and most advanced e-commerce trading platform for Internet games.
14 years of operation experience, a huge user base of 20 million, German localized market and technical team, backed by A-share listed companies Zhongying Internet.
Entry requirements
1. Provide the company business license.
2. Formulate store delivery policy and store return policy.
3. Account number for collection (such as Paypal, PayPal, Wan Li Remittance, etc.) 4. German VAT tax number.
Platform advantages:
1. The European region has great influence.
Active users are too dry.
German-speaking area game virtual goods trading market vane
Market opinion leader of European game sales industry
2. Core technological advantages
Self-developed operating system
"Optimization+Push" Algorithm Program
Anti-fraud system
3. Low cost and zero risk
There is no charge for moving in.
Short payment settlement cycle
Low operating cost
4. Excellent service
Yingde bilingual customer service is online 24 hours a day, 7 days a week
Localization operation team
1V1 Exclusive Account Manager
The official cooperation channel of Moga MMOGA POWER, click to view > > >
20、Wisecart:
The e-commerce platform for European users was officially launched in August 2021. Germany and Spain will be the first two markets of Wisecart, and then they will expand to other European markets.
Platform features:
1. Financial staging: lowering the trading threshold for buyers.
2, platform subsidies, higher profits for sellers-let the sellers benefit.
3. Buyers are more sticky: continuous financial services provide more sticky buyers.
4. Multilingual service: Wisecart provides customer service translation service for communication between sellers and buyers, and provides free manual translation of product information for potential sellers.
Seller’s rights and interests:
1. Free commission for the first three months; After three months, the monthly commission will be 5% if the monthly sales amount is 0-500,000, 3% if the monthly sales amount is 510-1 million euros, and 1% if the monthly sales amount is more than 1 million euros.
2. Logistics: overseas warehouse rental fee is exempted within 30 days, and the tail delivery fee of hot products on the platform is subsidized by Euro3,000.
3. Operation: The platform operation manager provides guidance throughout the operation process, including product selection, operation strategy, problem feedback, platform activities, etc.
Commodity categories: digital mobile phones, outdoor sports, household appliances, computer office, personal care and cleaning, maternal and infant children’s wear, home improvement, international famous brands, household kitchen utensils, bags and handbags, toy musical instruments, watches and jewellery, family security, pet life, and craft gifts.
Settlement policy:
Safe payment method: use the third-party cross-border payment platform to make the payment, and make the payment according to the daily statistical data T+7~14 days (T: after the buyer confirms the receipt or logistics shows that the payment is appropriate).
Hugo settled in the seller’s special rights:
1, 3 days to open the store quickly.
2, full-time official manager docking
3. Seller’s fee reduction and exemption: the commission is reduced to 12.31, and the goods are free of storage fees and traffic support for the first 30 days of warehousing.
Entry threshold:
1. Legal business license and relevant company background information, and agree to provide the company’s financial statements for Wisecart’s review when necessary.
2. Legal person ID card
3. Clear photos of the legal person holding the ID card and business license.
4. Screenshot of the sales of Youshang Store in the past three months, which must meet 5000 E/m.
Wisecart official cooperation channel, click to view > > >
21、Rue du Commerce:
Rue du Commerce is an e-commerce platform in France. Since its establishment, the platform has continuously expanded its business scope, from 3C vertical e-commerce in its early days to comprehensive e-commerce, including 3C electronics, video, mobile phones, household appliances, home, gardens, fashion, beauty and health, sports and leisure, food, culture and other products.
Platform advantages:
1. The average customer unit price is high (329 euros), and customers have strong purchasing power.
2. China sellers have a large space and the market is not saturated.
3. Compared with other platforms, the commission rate has advantages.
4. Chinese customer service helps to settle in, and provides the operation guide in Chinese (MIRAKL platform).
5. Settle accounts three times a month (1st, 11th and 21st), and the collection period is short.
6. MIRAKL background, which has been favored by many e-commerce platforms, is easy to operate.
7. Rue du Commerce is an e-commerce platform under Carrefour, the largest supermarket retail group in France, and has received strong support from the group.
Consumer groups:
According to the analysis of Lengow’s French music sales data, the main consumers of Rue du Commerce are high-income groups aged 25-49; 54% are men and 46% are women.
Entry conditions
1. Enterprises must provide business licenses when they settle in;
2. French customer service handles the buyer’s daily consultation;
3. English or French operators are responsible for communicating with the platform;
4. Reasonable logistics period;
5, cross-border e-commerce experience, European and French platform sales experience is preferred, with store links.
Platform fee:
Like most platforms, sellers can register their accounts directly on Rue du Commerce for free, and the monthly rental fee is 40 euros. The commission fee depends on the product category and includes taxes.
Hugo settled in welfare:
1. Rent free for three months.
2, KYC green channel for 1-3 days
3. Flexible commission rate
4, the official manager priority service treatment
5. High-quality seller traffic support, free exposure, home page advertisement, etc.
Rue du Commerce official cooperation channel, click to view > > >
22、MYTOYS GROUP:
Germany’s leading home shopping e-commerce platform ranks first in the sales of toys and children’s products in the German market! The online market share of this category ranks second in Germany, second only to Amazon in Germany.
Hot category:
1, toys, mother and baby, sports, shoes, home textiles, home decoration
Requirements for platform entry:
1. German VAT number where the company entity or delivery warehouse is located in the EU.
2. The goods use European EAN bar code and cannot be sold with others.
3. The return address in Germany or the European Union corresponds to the bank account number.
4. The account holder must be consistent with the company name, and the return package sheet must be attached when delivering the goods.
Platform fee:
1. 0 Settlement fee
2. The monthly rent is 39 euros (6 months’ monthly rent can be exempted if you move in through Hugo. com).
3. The platform commission is 15%
The official cooperation channel of MYTOYS GROUP, click to view > > >
(Source: Global Platform Lookout)
The above content belongs to the author’s personal opinion and does not represent Hugo’s cross-border position! This article is reproduced with the authorization of the original author, and it needs the authorization and consent of the original author. ?